
Pythonによるデータ抽出からインタラクティブWebアプリまでの実践記録
はじめに
最近「アメリカではしかが流行している」というニュースを目にしました。ワクチンで防げるはずの病気が再び広がっている現実に驚くと同時に、「日本、特に東京では今どんな感染症が流行しているのだろう?」と気になり、調べてみることにしました。
そこでたどり着いたのが、東京都感染症情報センターが発行している「感染症週報(TIDWR)」です。
東京都感染症情報センター|週報アーカイブ
https://idsc.tmiph.metro.tokyo.lg.jp/weekly/
東京都感染症情報センター(TIDSC:Tokyo Infectious Disease Surveillance Center)は、東京都健康安全研究センター内に設置されている部門で、都内の感染症発生状況を把握・分析し、都民や医療機関に向けて情報提供を行う機関です。インフルエンザ、麻しん(はしか)、RSウイルス、新型コロナウイルス感染症などの動向を継続的に集計・公表しています。
その「感染症週報」では、小児を中心とした定点報告感染症だけでなく、インフルエンザやCOVID-19など成人・高齢者に関係する疾患の情報も掲載されています。ただし、その形式はPDF。内容も表が中心で、専門知識がない人にとってはとても読みづらく、流行傾向を直感的に把握するのは困難でした。
「せっかくの貴重なデータなのに、これではもったいない!」そんな思いから、週末の3時間でPython可視化アプリを作ってみました。ChatGPTや生成AI搭載コードエディタCursorとのやりとりを通じ、AIとの協働による課題解決のスピード感とデータ活用の楽しさを実感するプロジェクトになりました。
データの出所と課題点
東京都感染症情報センターが毎週発表している週報は、都内の感染症の発生状況を詳細にまとめた信頼性の高い公的データです。ただ、その形式がPDFであるために、傾向を把握しにくく、一般利用にはハードルが高いのが現実です。
特に、小児感染症に関心を持つ保護者や教育現場にとって、「いま、何が流行っているのか」「どの疾患が増えているのか」を一目で把握できるような視覚的な手段が求められていると感じました。そうした課題を、誰でも扱えるWebアプリとして解決したいと考えたのです。

アプリの概要と機能
今回作成したアプリは、PythonとStreamlitで構築したインタラクティブなWebアプリです。
主な機能は以下の通りです。
- 感染症週報のPDFを自動取得し、必要なデータを抽出
- 感染症名を選んで、週ごとの感染者数をグラフ表示(複数選択可)
- 折れ線グラフとヒートマップの切り替えが可能
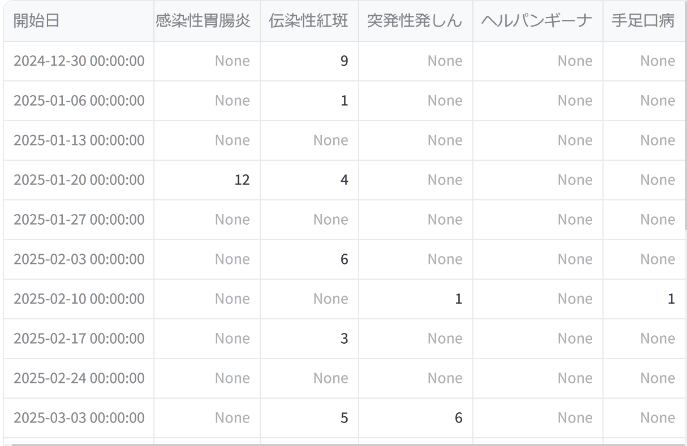
- 元データを表形式でも表示
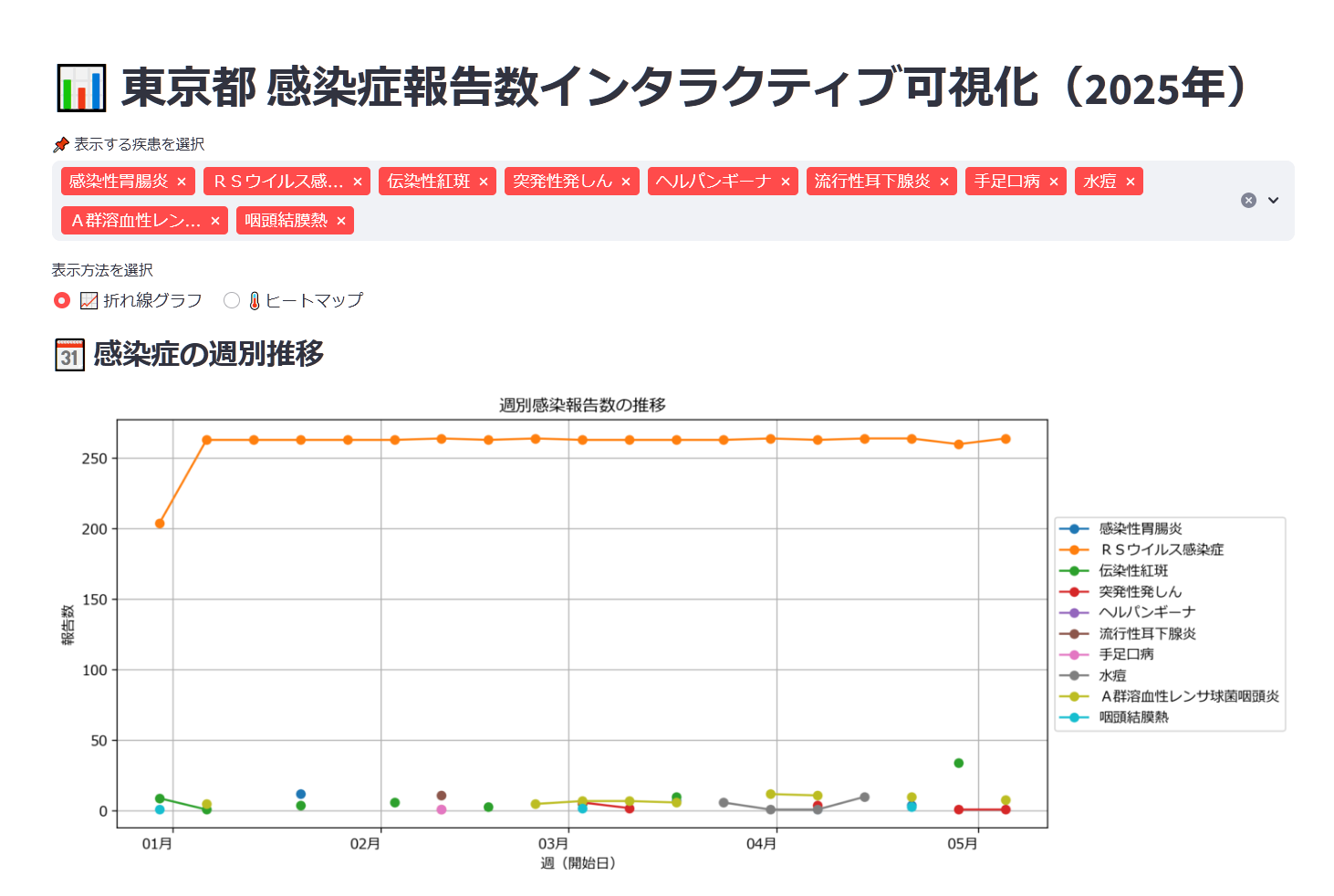
折れ線グラフとヒートマップの切り替え。
まずは、各感染症ごとに色分けで感染報告数の推移がわかる折れ線グラフモード。折れ線グラフでは、流行のピークや減少傾向が一目瞭然ですね。
可視化により読み解けること
- RSウイルス感染症は年始からずっと 200件を超える高水準で報告が続いています。
- 通常、秋〜冬に流行することが多い疾患ですが、近年は春先にもピークが出る傾向があります。
- 他の疾患(手足口病、水痘など)はいずれも報告数が10件未満で推移し、安定しています。
次に、感染症の報告数が多ければ多いほど色が濃く表示されるヒートマップモード。
ヒートマップでは、複数の疾患の比較や、週ごとの変化が直感的に把握できます。

可視化により読み解けること
- RSウイルス感染症の報告数が全週にわたって圧倒的に多く、常時260件前後を維持しており、他疾患と比べて突出している。
- 他の感染症は週ごとの変動が大きく、流行の兆しが見える疾患もある(伝染性紅斑が第19週に34件と急増)。
- 発熱・呼吸器系疾患以外の小児感染症(ヘルパンギーナ、手足口病など)は、全体的に低水準で安定している。
このような疾患ごとの週別比較が一目で把握できるのは、ヒートマップならではの利点です。
ChatGPTやCursorエディタを活用しながら、表現の微調整やデータ形式の整備、UI構成の工夫などを、対話的かつスピーディーに実装することができました。
作成のステップ
PDFの自動取得とデータ抽出
この工程はいわゆる「ウェブスクレイピング」に該当します。東京都感染症情報センターが公開しているPDFは、週番号に応じた規則的なURL構造を持っているため、Pythonで自動的に取得しやすい形になっています。
ウェブスクレイピングを行う際には以下の点に注意が必要です。
- 公的機関やサイトの利用規約に反しないこと
- アクセス頻度を過剰にしない(サーバー負荷に配慮)
- 利用目的が非営利・公益であることを意識する
今回の取り組みでは、1週間に一度更新されるデータを対象とし、低頻度・低負荷の範囲で自動取得しています。
週報PDFは「https://idsc.tmiph.metro.tokyo.lg.jp/assets/weekly/2025/01.pdf」のように週番号を含む規則的なURLで公開されており、Pythonで自動的にダウンロード・処理が可能です。ウェブ上のコンテンツをPyMuPDF(fitz)を使ってPDF内のテキストを読み取り、正規表現で対象の感染症名と報告数を抽出しました。
データの構造化
取得したデータをpandas.DataFrameで整形し、週番号から週の開始日(例:2025-01-06)に変換。これにより、時系列グラフの作成や、季節との関係を視覚的に追いやすくなります。
可視化アプリの構築
ChatGPTにアイディアを相談して必要な機能や要件を決め、原形のコードを書いてもらった後、コードエディタCursorのエージェントとの対話でコーディングを進めます。

実際のアプリ操作と使用
コードを実行するとウェブブラウザでアプリ画面が開きます。
表示する疾患を選択のチェックボックスで感染症を選択すると、グラフに描画したい項目を選択できます。
たとえば、「感染性胃腸炎」「RSウイルス感染症」「水痘」を選択すると、それぞれの週ごとの感染者数をグラフで確認することができます。
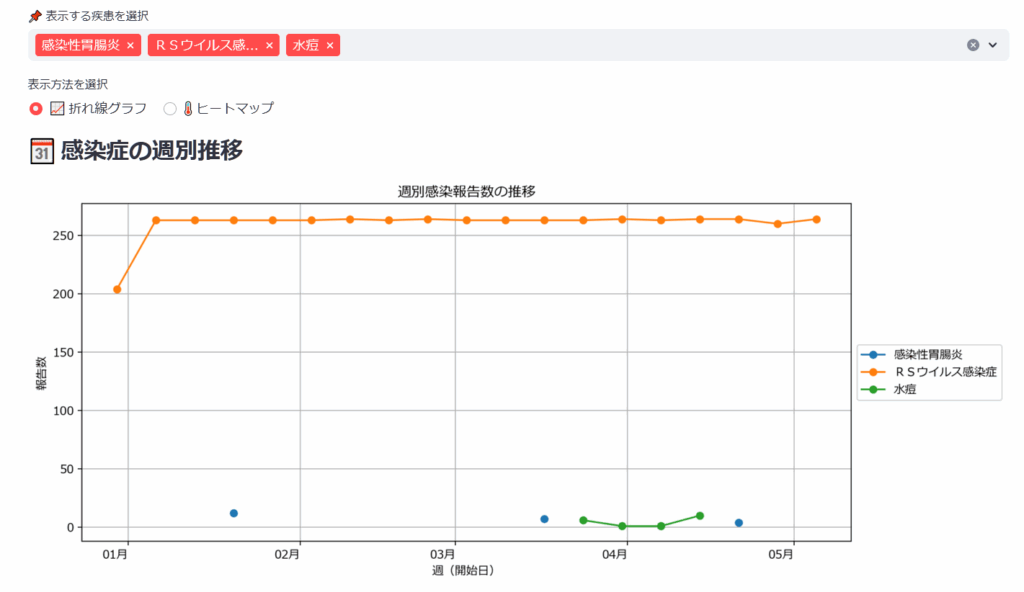
元データは第1週、第2週という週次での区切りとなっていますが、X軸には「1月」「2月」といった月表示を出し、時系列を直感的にわかりやすくします。ChatGPTとの対話により、適切な日付形式の選択やラベル配置も短時間で解決できました。

非エンジニアの方でも、クリック操作だけで視覚的に情報を得られる点が大きな特徴です。
今後の展望
今回のアプリは、あくまでプロトタイプですが、今後さらに以下のような機能拡張が考えられます。
- 保健所別に地域の流行状況を可視化(foliumやplotlyによる地図表示)
- 年齢層別の感染状況(例:0〜4歳、5〜9歳など)
- 前週比や増減率の自動算出とグラフ表示
- 時系列モデル(SARIMAやProphetなど)を用いた今後の感染傾向予測
- 定期的なデータ更新とSlack等への自動通知
教育・行政・医療など、さまざまな分野での活用が期待できる形に育てていきたいと考えています。
おわりに
「貴重なデータがあるのに、活用されにくい」── そんな状況を少しでも変えるきっかけになればという想いで、このアプリを作ってみました。
ChatGPTやCursorのようなAIツールを活用することで、思いつきからプロトタイプまでが驚くほどスムーズにつながりました。Pythonを使えば、ちょっとした問題意識を形にすることができる。そんな体験を、今回あらためて実感しました。
今後は、他の自治体データや気象・災害・教育などの分野にもこの仕組みを応用し、「役立つデータを、使いやすくする」取り組みを広げていければと考えています。
※この記事で使用したアプリやコードについては、ご希望があれば提供いたします。
📘 Pythonを基礎から学びたい方へ
このようなデータ活用や可視化に役立つPythonプログラミングの基礎を、わかりやすく学べる講座を開講しています。
プログラミング未経験の方にも丁寧に解説しながら、実用的なスキルを身につけていける内容になっています。ぜひご覧ください。





コメント